Kedro Dojô
O Dojô sobre Kedro foi gravado e o vídeo está disponível no sharepoint.
Kedro
O Kedro é uma framework Python de código aberto para criar código de ciência de dados reproduzível, manutenível e modular.
Ele usa as melhores práticas de engenharia de software para ajudar a criar pipelines de engenharia e ciência de dados prontos para produção.
O Kedro está em incubação no LF AI & Data Foundation.
Por que usar Kedro?
-
Coloca a engenharia de volta na ciência de dados porque pega emprestado conceitos da engenharia de software e os aplica ao código de aprendizado de máquina. É a base para um código de ciência de dados limpo.
-
Fornece a estrutura para criar pipelines de dados e de aprendizado de máquina mais complexos. Além disso, há um foco em gastar menos tempo no tedioso "encanamento" necessário para manter o código de ciência de dados
-
Padroniza os fluxos de trabalho da equipe; a estrutura modular da Kedro facilita um maior nível de colaboração quando as equipes resolvem problemas juntas.
-
Faz uma transição perfeita do desenvolvimento para a produção, pois você pode escrever código exploratório rápido e descartável e fazer a transição para experimentos de código fáceis de manter e compartilhar rapidamente.
Comunidade
Principais funcionalidades
- Template de Projeto
Um modelo de projeto padrão, modificável e fácil de usar baseado em Cookiecutter Data Science.
- Data Catalog
Uma série de conectores de dados leves usados para salvar e carregar dados em vários formatos e sistemas de arquivos diferentes, incluindo sistemas de arquivos locais e de rede, armazenamentos de objetos em nuvem e HDFS
- Abstração de Pipeline
Resolução automática de dependências entre funções Python puras e visualização de pipeline de dados usando Kedro-Viz.
- Padrões de Codificação
Desenvolvimento orientado a testes usando pytest, produza código bem documentado usando Sphinx, crie código padronizado com suporte para flake8, isort e black e faça uso da biblioteca de log padrão do Python.
- Deploy Flexível
Estratégias de deploy que incluem deploy de máquina única ou distribuída, bem como suporte adicional para deploy em Argo, Prefect, Kubeflow, AWS Batch e Databricks.
Principais conceitos do Kedro
Consulte Kedro concepts
-
Node
No Kedro, um nó é um wrapper para uma função Python pura que nomeia as entradas e saídas dessa função. Os nós são o bloco de construção de um pipeline e a saída de um nó pode ser a entrada de outro.
-
Pipeline
Um pipeline organiza as dependências e a ordem de execução de uma coleção de nós e conecta entradas e saídas enquanto mantém seu código modular. O pipeline determina a ordem de execução do nó resolvendo as dependências e não necessariamente executa os nós na ordem em que são transmitidos.
-
Data Catalog
O Catálogo de Dados Kedro é o registro de todas as fontes de dados que o projeto pode usar para gerenciar o carregamento e salvamento de dados. Ele mapeia os nomes das entradas e saídas dos nós como chaves em um DataCatalog, uma classe Kedro que pode ser especializada para diferentes tipos de armazenamento de dados.
Arquitetura
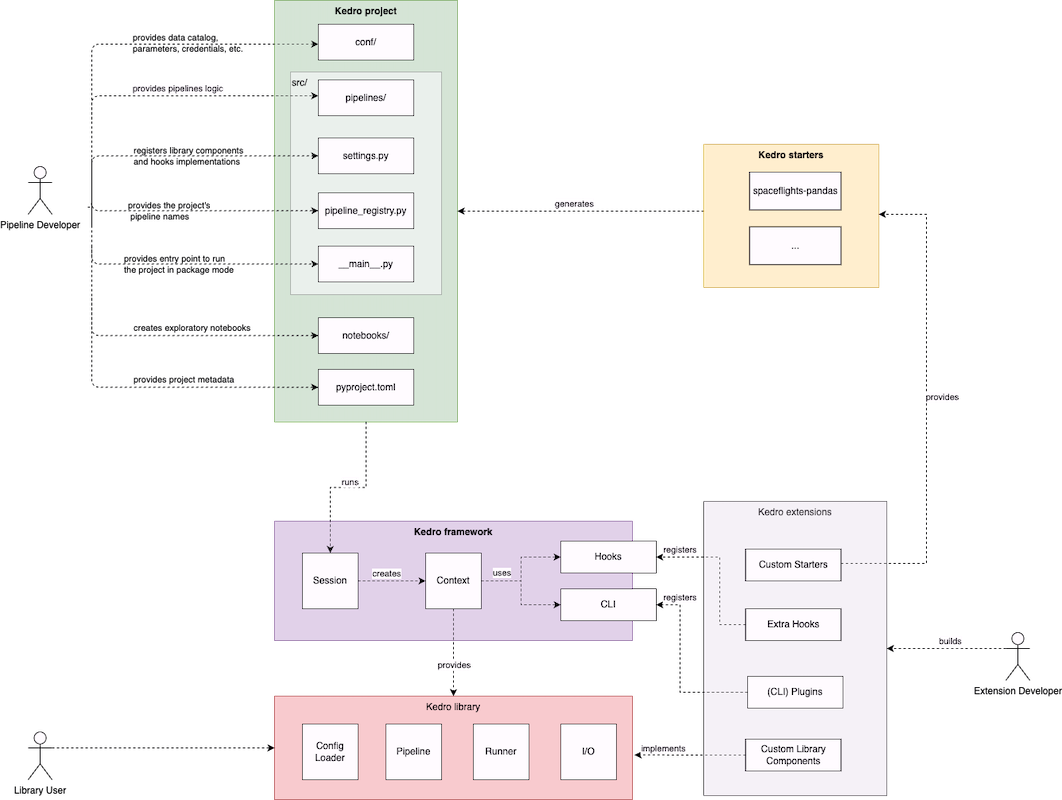
- Kedro framework
- Kedro library
-
Kedro extensions
-
kedro starters
- Kedro project
Desenvolvendo com o Kedro
Consulte o Kedro project development workflow
-
Configure o template do projeto
- Instale o Kedro:
pip install kedro - Crie um novo projeto:
kedro new - Instale as dependências:
kedro install - Instale as dependências de pacotes adicionais:
kedro micropkg pull --all -
Configure os loggings, as credenciais e outras configurações necessárias no diretóio
conf -
Kedro Viz
pip install kedro-vizkedro viz --autoreload
- Debugging
- Instale o Kedro:
-
Configure os dados
-
Adicione os dados no diretório
data. - Não precisa ser locar-
What is data engineering convention?
Raw
Modelos de dados de origem inalterados. Geralmente não estão tipados. Formam a fonte de verdadeIntermediate
Modelos de dados tipados. Por exemplo convertendo valores baseados em string em sua representação tipadaPrimary
Modelos de dados específicos do domínio limpos e transformados a partir das camadas anteriores. Formam a camada que será input do feature engineeringFeature
Modelos de dados específicos para análise contendo features definidas a partir dos dados da camada primary. Esses dados foram agrupados por área de análise e armazenados em uma dimensão comumModel input
Modelos de dados contendo todos os dados em relação a uma dimensão comumModels
Modelos de aprendizado de máquina pré-treinados armazenados e serializadosModel output
Modelo de dados contendo os resultados gerados pelo modelo com base nos dados de entradaReporting
Modelos de dados combinados das diversas camadas e otimizados para a criação de relatórios
-
-
Referencie os datasets em
conf/base/catalog.yml- https://kedro.readthedocs.io/en/0.17.4/05_data/01_data_catalog.html
- https://kedro.readthedocs.io/en/stable/kedro.extras.datasets.html
-
-
Crie o pipeline
- Crie as funções de transformação de dados
-
Construa o pipeline usando as funções como nós
- Crie os testes unitários e de integração
- https://kedro.readthedocs.io/en/stable/development/automated_testing.html
- https://github.com/kedro-org/kedro/discussions/1068
- https://github.com/kedro-org/kedro/issues/1271
- Crie os testes unitários e de integração
-
Escolha como executar o pipeline
-
Empacote o projeto
- Crie a documentação do projeto
- Empacote para distribuição
kedro packagekedro micropkg package <package_module_path>